There are so many articles about the topic of estimations in software-development, I can't even count anymore how many of them I read.
Even though, almost everyone still estimates effort or time by breaking down work into tasks and then assigning a single number to each of them.
It's really beyond me why this is still the standard. Maybe because methodologies like Scrum and tools like Jira encourage it?
But to understand why this is such a big problem, a fundamental problem of estimations needs to be understood first, not only by developers but also by managers and other stakeholders.
Estimations #
Let's get one thing out of the way: estimations are generally important and useful. They improve decision-making about prioritization, timing, deadlines and resource-planning.
Well, at least if everyone works together in good faith. The estimation process can also be abused and become a form of (corporate) power-play.
In those cases, there's no point in discussing about the how, so I'm going to focus on the happy-case here.
Single number estimations #
I said that it's a problem to estimate work by assigning just a single number per task. Even if it's t-shirt-size estimations.
Why is that?
Imagine you are a manager (or maybe you just are one) and your developers are always giving you precise estimates like 5 days or 3 months of work for a bunch of tasks or a project.
And then they always deliver on time. That sounds great right? The developers seem to know what they are doing. Makes it easy to rely on them and plan things.
Maybe surprisingly, this is actually not good. Here is how reality usually looks like:
| Developers estimates are... | Behind the scenes... |
|---|---|
| Almost always accurate | 1. The developers are adding way too much "buffer time" or 2. The developers are incompetent and repeat work instead of automating it |
| Almost always too low | Communication issues, incompetent management (often: top down pressure) |
| Almost always too high | Does not happen, your data is wrong :-) |
| 50% too high and 50% too low | 🦄 You found a unicorn |
Okay, fine, it's a bit exaggerated - but maybe less than you think.
Estimations are no divinations #
A common misunderstanding in the field of software-development is to think that with experience estimations must get better.
And it sounds logical at first because that's how it works in other fields: someone who has to build a house for the first time will have a hard time to estimate how long the whole thing takes. But after building houses for decades, their estimations will eventually become spot on.
Unfortunately, software-development is one of the very few professions where this is inherently different.
Software-development is ultimately the process of creating automations. Every piece of work that has to be repeated over and over again will sooner or later be automated.
Once that has happened, it can be used or produced so quickly that it is not even worth to include it into the estimation process anymore.
In consequence, the only tasks that actually make it into the estimation process are those that have not been automated yet - because they have not been built in this way so far. Thinking of it from that perspective, it's not a surprise why those estimations are comparably difficult.
But it's not only that. There are also many factors that simply cannot be estimated precisely when starting. For instance, a technical dependency that is required for the task at hand has an unexpected bug that needs to be worked around.
All in all, even if we try hard to estimate a task as precisely as possible, we inevitably end up with a probability distribution; and most likely a rather complicated one.
And since there are many factors which all vary in their own way, it is not unreasonable to assume that the outcome will often follow something that is not far from a normal distribution.
So it might actually look something like this:
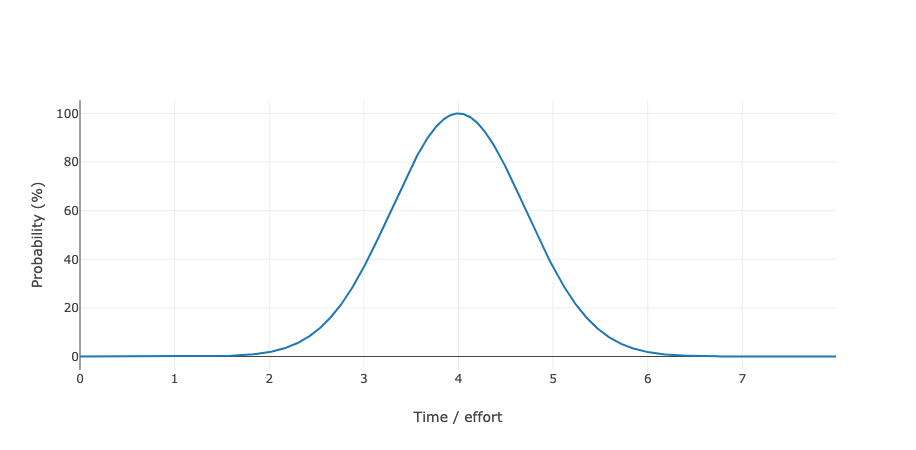
The graph shows how likely it is (in percent) that the task will be finished in a given amount of time on the X-axis (in days or weeks or months - it doesn't matter here).
To come back to the table from the beginning - what would the developer give as a single number based on that distribution?
Due to the symmetry it clearly looks like a 4 on average.
However, the chance for the task to be finished after exactly 4 days is extremely low; it will sometimes be a bit more and sometimes a bit less, maybe 3 or 5 days.
One day difference might not sound like a problem but what if those are months not days? What if it's a law that we are supposed to follow with a given deadline?
Looking at it from another perspective: when using such a technique for estimations to decide on deadline dates, half of all deadlines will be missed.
By now it should be clear why single-number-estimations are very limited.
But I will add another example to make it even more obvious.
Let's imagine there is a complicated feature that needs to be implemented by a single developer Alice.
The feature requires interoperation between multiple systems, including a system that Alice is unfamiliar with.
However, there is another developer, Bob, who knows all about the system and can share that knowledge to decrease development time drastically.
But Bob is busy with another urgent and critical project and it is yet unclear if he will be able to provide any support at all.
How does the probability distribution look like in this case?
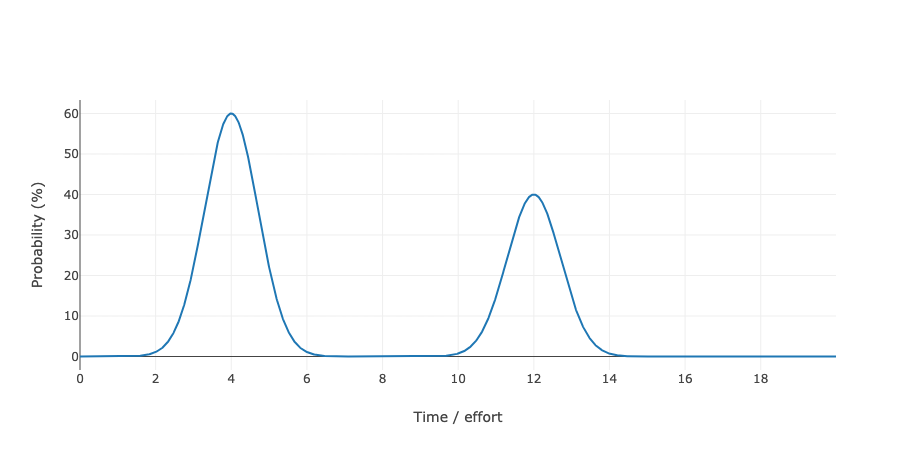
There are two peaks, one at a low effort (~4 days) when receiving a bit of help by the other developer and one without their help (~12 days).
Just estimating the mean value here is even more misleading than in the previous example. The mean of this distribution here is 7.2, but when looking at the graph we can see that the chance of the outcome to actually be 7.2 or even close to it is pretty much zero.
Using the mean alone is obviously a terrible idea.
Unfortunately it's unrealistic to model the effort with a precise mathematical distribution like above for every single task, let alone projects that consist of hundreds or thousands of subtasks.
Tackling the shortcomings #
In reality, simple mean values are mostly used when doing estimations.
And since they are lacking, how do the estimating developers usually attempt to work around this problem in various ways?
Let's look at a couple of the common ones:
Buffers #
After being yelled at by their manager for a missed deadline, "buffers" will be added to the estimation values. This is very common.
Doing so is usually based on gut-feeling, or at least I've never seen a guideline for it or even a standard.
Sometimes the deadline is communicated through multiple layers and every person adds their own buffer to protect themselves until all meaning is lost.
All of that does not help in cases like the Alice/Bob example. Even fairly big buffers possibly won't really help if the second probability-peak isn't covered.
In the end, buffers lead to suboptimal planning and resource allocation and for example significantly increase the time-to-market.
Splitting tasks #
Another classic. Once it is understood that single-number estimations don't work well, the size or scale of the estimated tasks is made out to be the root of the problem.
Those tasks are just all too big and can't be estimated precisely! Hence, tasks that are too big are must be split into a smaller tasks and so on until the estimation for every task is below a certain threshold.
There are indeed some benefits in splitting big tasks, it's not like this is a bad idea in general. But it comes with problems. Estimation is a time intense process and the more granular the tasks become the more friction and bureaucratic process is added to manage them.
In addition, the effort to actually combine the tasks into an end result is often missed or underestimated, making it so that the sum of the child tasks does not match the whole project.
Finally, sometimes it's just not possible to meaningful split tasks further.
Ultimately, it is not a solution to the single-number estimation problem; though it can aid in other ways, such as improving the common understanding of every task within the team.
Side channels #
There are more workarounds, but the last one I'd like to mention here is the communication via other channels.
If tools or processes force to enter single number, people sometimes step up and communicate that the estimation might be value X but that the confidence into that estimation is low.
This is a reasonable approach and better than nothing, but it is also unstructured and unsuitable as a professional solution in general.
Confidentiality intervals #
My preferred practical but effective solution to improve the situation without making it too complicated is the use of confidentiality intervals.
The idea is to describe two numbers instead of one: the lower and upper bound which capture 90% of the expected outcomes. For example, if the interval is defined as [2, 5] and we measure in days, then that would mean that the chance is 90% that the task will take between 2 and 5 days. And only 10% chance that it will take less than 2 or more than 5 days.
It doesn't really matter what percentage we choose - 90% or maybe 80% or 75% are all fine. What matters is that we have introduced a way to indicate the trust we have in the precision of the estimation.
(Note: the classical way would be to use the mean and the variance or standard derivation to describe a probability function. However confidence intervals are a bit more intuitive in their usage when it comes to most estimation processes)
How to use confidentiality intervals #
1.) We decide on a timeframe and ask the developer to estimate the probability that the feature will be completed within that timeframe.
2.) We ask the developer what the deadline would have to be so that it will only be missed with a chance of 10% (or some other percentage)
Approach 1.) is useful in cases where a timeframe is set by a 3rd party and we can't control it.
For instance, a legal requirement that needs to be complied with by a certain date.
In that case, we can gain information about how likely it is that the deadline won't be met. And by knowing that, we can react to it, for example by assigning more resources or preparing for the consequences of missing the deadline.
Approach 2.) is more useful in cases where we can control the deadline. We might want to release a feature and we need to communicate it in advance, for instance so that the marketing department can prepare, book and release and advertisement campaign.
In this case we can decide on how much of a problem a delay would be and in consequence set the appropriate confidentiality level. We then ask the developer to tell us about the deadline.
Bonus #
I hope that I could shed some light into why there are often problems with estimations in software-development and also how to improve on it - for both technical and non-technical folks.
If you made it that far, here's another question: why is usually only the time/effort estimated that is required to complete a task or project, but not the time/effort to maintain things?
I believe that this is one of the reasons why companies or teams eventually get stuck and become unable to deliver anything new. But this is for another article. :-)
Should you have solved this mystery then please let me know in the comments. Also, I would be happy to learn if you found an even better practical solution for estimation than confidence intervals.